Abstract
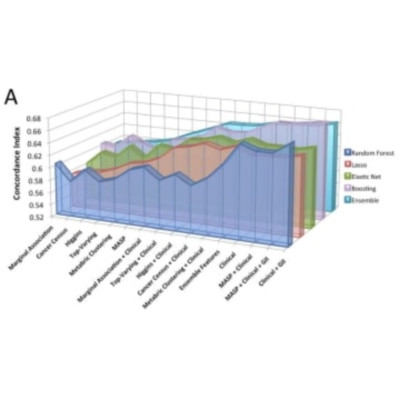
Breast cancer is the most common malignancy in women and is responsible for hundreds of thousands of deaths annually. As with most cancers, it is a heterogeneous disease and different breast cancer subtypes are treated differently. Understanding the difference in prognosis for breast cancer based on its molecular and phenotypic features is one avenue for improving treatment by matching the proper treatment with molecular subtypes of the disease. In this work, we employed a competition-based approach to modeling breast cancer prognosis using large datasets containing genomic and clinical information and an online real-time leaderboard program used to speed feedback to the modeling team and to encourage each modeler to work towards achieving a higher ranked submission. We find that machine learning methods combined with molecular features selected based on expert prior knowledge can improve survival predictions compared to current best-in-class methodologies and that ensemble models trained across multiple user submissions systematically outperform individual models within the ensemble. We also find that model scores are highly consistent across multiple independent evaluations. This study serves as the pilot phase of a much larger competition open to the whole research community, with the goal of understanding general strategies for model optimization using clinical and molecular profiling data and providing an objective, transparent system for assessing prognostic models.